It is a capstone project
Project Overview
The Nuclear Instrumentation Laboratory Information System (LIS) is a capstone project for my final college stage. It has been designed to support various business processes, including asset loans, asset managements, activity logs, appointment bookings, and a student material repository.
This project aims to reduce laboratory costs, increase researcher work efficiency, and enhance laboratory accessibility to laboratory resources.
Moreover, permitted visitors can also simulate decay computation for radionuclides stored in the laboratory. This feature enables students and researchers conveniently access radionuclides data and utilize computed value for their work, eliminating the time-consuming of manual calculations.
Furthermore, this project embraces data interoperability, ensuring reliability of communication between two or more platforms/services while maintaining seamless experience for users.
You can access the project repo on this Github Repo
Background & Impacts
Background
The laboratory’s stakeholders and management have identified potential issues in future laboratory operations :
- Runs out of paper and books for logging activities
- Manage all documents using two different methods, physical and digital forms without any proper cataloging.
- Physical documents have lousy reliability.
- Managing asset loans and asset maintenance schedules.
- Students and researchers were driven to difficulty in finding references for their works.
- Students and researchers often waste their time finding and calculating radionuclides’ intrinsic data, such as decay activity, decay time, and other elements’ meta data values.
- External or public had no convenient ways to appoint the laboratory for research or study (yep, the laboratory is open to the public, actually ).
Impacts
- Reducing laboratory costs by approximately 20-25% by digitizing system to manage and store physical documents, such as activity logs, reference and study materials, and assessment papers.
- Transform all information into a unified, fully digitized environment. This project will make an accessible and cost-effective platform by leveraging remote server to run the application.
- Provides proper study materials and reference repositories for students and researchers to support their works. Indeed, we can use an existing platform like Google Drive. However, managing links and forcing visitors to search and manually download documents were inefficient.
- Improves the accuracy of tool and machine maintenance schedule to nearly 100% as maintenance dates are prearranged for each machine.
- Offers laboratory users precise and accurate element metadata and assists them in calculating decay rates and activities effortlessly.
Challenges
Several challenges have been addressed during the development process, particularly in planning, implementation, and third-party API integration.
First, in the planning phase, when translating several flow and business processes into a single coherent app. After that, implementing the Product Requirement Document (PRD) into functional code required careful execution and problem-solving.
Lastly, 3rd party API integration demanded extensive time and effort to ensure accuracy and efficiency during the process. I will elaborate on this process later in this article.
Tech Stack
This project utilize following tools :
- PHP 7
- Laravel 8
- Bootstrap 4
- JQuery
- PostgreSQL and pgAdmin
- Redis
The app then deployed on hostinger.
You can also get and read the radionuclide data on this IAEA’s site
Package Used
- Laravel Spatie to implement RBAC
- Laravel Excel to export and import excel files to and from database. But i did not use this package to handle 3rd party integrations.
- Laravel Socialite to add ability login using multiple OAUTH provider
Interesting parts
The rest of the development part is following standard process and is not particularly special. However, the most interesting aspect of this project is the third-party integration.
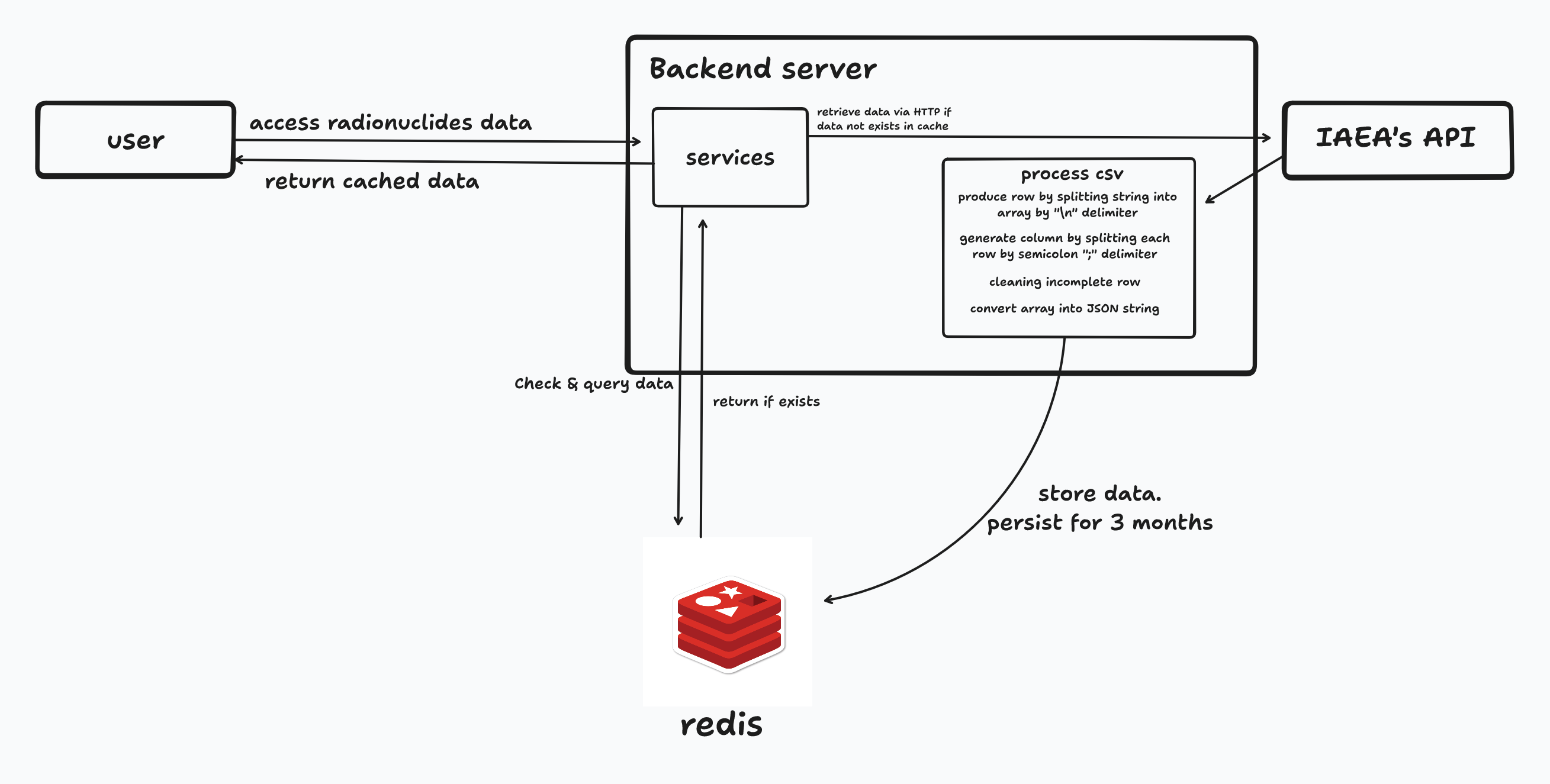
The data retrieved from the API formatted in CSV, though actually separated by semicolons and the line break ( \n ). Since I displayed the data using JQuery, which is Javascript-based, the most straightforward approach was to convert CSV to JSON for easier consumption. Next, the data had to be cleaned from invalid rows. Many rows lack of complete data making them unusable to read.
Another challenge is ensuring data interoperability between my app and IAEA’s API. Random jams were occured due to the IAEA’s API might not be designed for having high availability and quick response times. These delays could frustrate users. So, my solution was implementing caching strategy and asynchronous jobs. When an user accesses a radionuclide data for the first time, the backend caches the data for 1 year to reduce API dependency.
The leads to another question, “What about the calculated decay activities you mentioned earlier?”. The answer is that whenever the site administrator updates a radionuclide data, both the element’s metadata and calculated values are cached as well. To enhance user experience, cache updates run in the background ensuring seamless experience.
The processes I have explained before are illustrated in the following diagram.
Accessing Local Radionuclide data
The laboratory store radionuclides, each with it own unique metadata. Every usage of radionuclide and for any purposes, students or researchers should calculate decay time and activity using metadata such as half-life and isotopes number. Since IAEA is the highest authority responsible for setting standard of global atomic data, its data are considered valid.
For the first time user accessing radionuclide data (stored in the laboratory), the backend server check for any existing cached data. If no cached data is found, the backend retrieves data via HTTP, process the CSV response, and stores the structured data to Redis. Once the caching is complete, the service returns the stored data on Redis. Obviously, this was time-consuming for the first request, but subsequent request are significanly faster due to caching.
Auto-scheduling cached data and on update event
To resolve previous problem, the backend already scheduled auto update data every 3 months using Cron Job. This process is runs in the background, so the user experience will not be interfered.
Moreover, for every local radionuclide update, this will trigger auto-updating data. This process also runs in the background.

Published Paper
This project was also published to international conferences at ICCSET Conference at 2023. You can read the official published paper at AIP Conference Proceedings
Screenshots